
Intro: About Digital Experiences and Signs
(Special thanks to Gerardo Gonzalez and Andy Hawks, engineers at CivicActions, who worked on this project -- and this post -- with me.)
“Digital Experiences” are the next big thing someone at your company is almost certainly talking about. These include visionary technology that operates based on rich data that is timely and location-based, interactions between other services and products, and perhaps most importantly: content that is not reliant on a user manually driving the experience (as they usually might on a website or mobile application).
One common form factor for these experiences is the digital sign. Not all signs constitute a digital experience, but there is an emerging market for such devices and the management of the content / data that is flowing to them. This challenge is particularly exciting when considering the potential for massive scale, as digital signage is installed across large buildings, campuses, cities, or even countries/regions.
The transportation industry has long relied on such experiences. Airports and bus terminals were doing this well before it was a trend, using signage to power “digital” (or analog, depending on how long you’ve been traveling) experiences for the travelers passing through their doors.
A person can stand in front of a board for some period of time, and eventually they will see the status of their flight (or bus/train) get updated. Imagine though, what might happen if there was so much data that it could no longer be managed manually. What if the data wasn’t so simple as an arrival time? What if that data was constantly changing in a massive network of tracks, stations, and technology spread across a large city?
In New York, the Metropolitan Transportation Authority (MTA) represents the perfect use case for just such a system. They are the largest public transit system in the United States, with an average of 11 million riders daily. While some of the stations that serve the “numbered” links have digital signage, none of the lettered lines had any indication of when a train might arrive -- until this project started in 2017.

Now countdown clocks are currently being installed / enabled throughout New York. Each of these signs is a highly complex ecosystem that has to be entirely self sustaining. It has to know what to do with the data it is receiving, know how and where to display it, and know how to recover if the internet goes down for a short period of time. More, there will be over 2500 of these new signs installed throughout the city as part of an effort by the MTA to provide their riders with more information and technology in the stations.
This article will focus on the technical solutions that Acquia has implemented, along with its partner CivicActions, and how we have approached this scenario using Drupal and Amazon’s Internet of Things (IoT) service from Amazon Web Services (AWS). (If you're interested in a higher-level overview, please check out the Metropolitan Transit Authority case study on Acquia.com.)
System Architecture
At a high level, the architecture for this system is simple:
- Get data
- Organize data
- Display data on appropriate sign(s)
When considering data, there are several types: train arrivals, weather, time, messages, and slideshows. Each of these data types comes from one or more sources, and each has different data formats, granularity, and update intervals.
The first iteration of this architecture was a functional, yet unscalable “pull” based system. In the initial approach each sign was responsible for acquiring, parsing, and displaying its own data. The signs were constantly polling various APIs for arrivals information, messages, weather information, etc. While functional and elegant, this approach was flawed. Having the signs do all the work meant lots of redundant processing and API rate limiting. Also, there was a high risk that the signs could create a Denial of Service (DOS) scenario on our own hardware.
The proof of concept was released into a handful of subway stations in New York and was used successfully for months. While this approach was unscalable to cover the entire city, it worked sufficiently for the few dozen signs that were part of the conceptual phase. As we moved into the second iteration of the architecture, we had to accommodate “thousands” of signs, where the proof of concept was only capable of supporting a few dozen.
In order to accommodate such a large number of devices, we had to abandon the “pull” architecture for a more scalable “push” approach. We also introduced a central data acquisition, parsing, and sending approach that drastically simplifies the front end duties and exponentially reduces the number of requests against the provider APIs.
By centralizing the data tasks into a single location, we create opportunities both for streamlining our pipeline and bottlenecking it. It is critical that all components in this data pipeline run as quickly and optimally as possible.
Content Modeling
In order for raw data to be effectively (and efficiently) parsed and sent to the appropriate signs, our parsers must understand context. Unfortunately for us, none of the data feeds provide context (this is not uncommon). Data feeds, particularly those that update very rapidly, must be as streamlined as possible to cut down on size and processing time for the system that generates it in the first place.
This is where a content model comes in place. A key in the data (or several data fields) somehow map into the model, which then provides context for how the data should be consumed and handled by the system.
For the MTA, this content model needed to be representative of the assets in the city of New York. This model should create a digital representation of the various Routes (N,Q,R,W, etc.), Stations (Grand Central, Penn Station, etc.), Platforms (Uptown, Downtown, Mezzanine, etc.), Tracks, and Signs that will be included in the data.
A key component of the MTA system is the flexibility of our content model. Why? We’re using Drupal to manage it.
Each of the above assets is represented by a content type. Individual items in the content model are created as nodes, and then entity reference fields are used to provide the necessary context and relationships between the items. User experience is a major component of this feature as Drupal’s involvement allows non-technical users to log into the administration site (with the appropriate account access) and make changes to the content model on the fly.

The content model also has the added benefit of being available for any content that is created inside Drupal. As messages are created within Drupal, they can be targeted at various granularities (e.g. display across an entire Route or only on a single Platform).
We knew early on that we would pay a price for including Drupal in the content model in performance. Executing queries against the Drupal database, while well documented and easy to do, is not a particularly fast operation. Particularly as the number of objects in the database scales to include thousands and thousands of pieces of content. Particularly when data must be parsed and sent every few seconds.
To ensure we have the necessary speed, we must operate against a cache instead of Drupal itself. The content model is archived into an inventory file that the data pipeline reads every few seconds to provide the necessary context to the data. Any time the content model is changed on the Drupal side, it is re-cached and made available to the next iteration of data. This effectively gives us the performance of a “static” content model (very fast) with a flexible and user friendly method of updating it (Drupal) with none of the drawbacks of either solution.
Data Feeds
As mentioned previously, there are several types of data that the system must consume: train arrivals, weather, time, messages, and slideshows. Each type of data has its own unique data source, that is updated on regular (if different) intervals over an encrypted connection. Data is provided in either an XML or JSON format.
In order to gather data from these providers on regular intervals, we need regularly running jobs on a web server that can execute the necessary tasks. In our case, we are using cron jobs that execute Drush scripts which then kick off the appropriate data pipeline(s) for each of the data sources. We will discuss this in more detail later in the article.
Our data pipelines, starting with a data provider, are a perfect example of our approach to implementing an object oriented code base on this project. An abstract provider class provides key methods that are needed for any provider (regardless of its update interval, data format, etc.). We can then extend this base class for each specific provider to add additional clarity to the methods defined in the abstract class.
As a data feed updates and the most current data is acquired by the provider, it is validated against a model that defines the expected structure, data format, and fields. This helps ensure that invalid or altered data cannot be pulled into the pipeline. The model also provides a structure for basic transformations. For example, our train data arrives in a milliseconds format and is displayed in a minutes format.
All of the needed functionality for a provider, model (and other key features for the data pipelines) are wrapped in Drupal modules (mostly for the convenience of being able to directly interact with them via Drush). These modules share many common features and functions as they all extend the same base classes and methods. This makes maintaining the various pipelines, learning the system, and doing any refactoring and updates significantly easier.
Data Parsing
The next step in the pipeline is categorizing the data. Most of the data coming through our system is only relevant given context (weather and time being the exception to this rule, as these are currently constant throughout all signs). However, there is no context in the source data. This is where the content model comes into play as we break the single, large data sets into smaller components.
Let’s look at the actual transit data, as an example. A single data file contains enough data for thousands of screens and is accurate for a few seconds (until the next data file is generated). The only context that arrives in the data file is a marker that identifies the station. The combination of station id, direction, and tracks can be used to extrapolate exactly where the data must go, but that context does not exist in the data file itself.
Once the data is acquired by the provider and checked against the model, the categorizer takes over. Using the content model as a map, it breaks apart the large data set and bins it by platform. The station id in the data is used against the content model as a reference, and additional information in the data file related to specific track and direction are all used to properly bin the data. The categorizer also re-orders the data. In our case, we sort it based on the arrival time, but there could be other transformations performed here as well.
Since each of the data feeds has slightly different requirements in terms of organization, each Drupal module / feed has the potential to contain a custom categorizer. This is an important as some of the data is relevant at a platform level (train data) and some of the data is relevant at a screen level (which is more granular).
Once the transformations are completed by the categorizer, it’s time to send the data.
Data Transmission
Getting data to the signs themselves represent a significant challenge. With a normal web application running on a personal device, it is assumed that a user will eventually reload a page, navigate to a new page, etc. With a sign, there will never be a “user.” This means that once a sign comes online, it has to maintain a connection to its data source for long periods of time. While there are many types of messaging and communication protocols, each of them has drawbacks and limitations. We ultimately decided that a websocket is an ideal solution to this problem, given its ability to stay open for long periods of time and the relatively low overhead of the connection (since it doesn’t have to make a request to get data).
As the data comes out of the categorizer, we use our sender classes to transmit the data. In some scenarios we want that data to actually go to a screen, but in others, for testing or automated build purposes, we don’t. As a result we have various sender classes that can be called that can customize the behavior of the pipeline.
Regardless of the data’s destination, the sender class wraps the categorized data in a message object. This allows the various data that comes from each provider to still be unique for its purpose, but ultimately be sent in a consistent format. If the data is being sent through the websocket, the sender packages a destination for the data in the object, based on the platform or screen that is receiving the data, and a credential object that will be used for authenticating the data as it is sent.
AWS IOT
Our primary sender class is designed to interact with the AWS IOT service. As a service, we don’t have to worry about scaling up/down as message traffic changes over the course of the day. AWS handles all of the autoscaling as needed. The IOT service also nicely fits our use case as it provides a MQTT protocol for websocket traffic, which is a lightweight protocol specifically designed for sending messages between devices.
The standard approach when using IOT is to define various Topics in the service. Topics are used both as a place to push data (from the sender class) and as a place to subscribe to data (from the front end). As soon as our sender class pushes data into a topic, any devices (screens) that are connected to that topic receive the payload in a matter of milliseconds. This is powerful as it allows us to subscribe multiple devices to the same topic and push data to more than one sign at the same time!
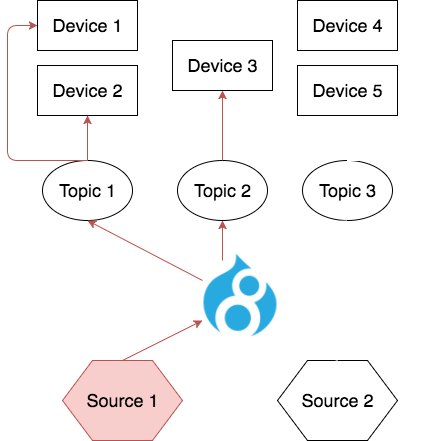
We used the AWS PHP SDK to create our own AWS Sender class. We also wrote a simple Drupal module that, through configuration, manages AWS credentials (key based) and endpoint. This allows our sender to dynamically generate credential objects without relying on hard coded credentials. It also allows us to avoid certificate based authentication since managing certificates on thousands of devices is a daunting task. By using MQTT communication (vs. http requests) we can bypass the certificate requirement entirely, and send credentials over an encrypted connection as part of the sending process. We can also update and change these credentials as needed thanks to our authentication module without having to re-deploy the code. We are actively working to open source this module so others can benefit from it.
Device Communication
As we began on Phase 2, our earliest goal was to get basic communication up and running. This initial architecture used the most basic approach to IOT: authenticate, send data to topic, push data to devices. All energy was put into creating a proof of concept in the PHP and React code that would allow us to demonstrate the a basic data pipeline: get data, parse data, send data, see it on a screen. This early version of the code didn’t handle scale, didn’t have any error handling, wouldn’t reconnect if the connection dropped, etc. BUT, it did transmit data. It was a good first step.
As we got closer and closer to production code, we realized that we had a problem. The basic Topics in the IOT have no history. As soon as data is pushed to the Topic, it’s gone. This isn’t necessarily a problem as long as all of the devices are connected when the data is pushed. However, if a device disconnects or there is any interruption in communication once it reconnects it will have to wait for the next payload before it has anything to show. In our use case, we send train data multiple times a minute, so this isn’t a huge concern. However, other types of data are sent much less frequently. If there is no history on the topic, we now have a dilemma: do we send data more frequently than we need to so we can cover the “just in case” scenario that a device might have been disconnected, or do we run things at the proper intervals and have signs that are missing data?
Ultimately we discovered the Device Shadows. These are special variants on the typical Topics that DO store history. If we would have known about this part of the API, we would have started here. The shadows work more or less exactly like the standard topics, they just use slightly different portions of the SDK to function, and the naming conventions for the Topics are different. The biggest advantage of a device shadow is that if a device does get disconnected, when it reconnects it automatically receives the last payload that was sent to the topic.
We are still using this version of the code in our production environment today. However, we did run into one final roadblock that we had to solve. Once our codebase was mature enough for production, we ran in depth simulations of the entire data pipeline. We ran several times the expected data load through each of the classes to see how they would perform under load, and we discovered a problem. We could acquire and parse the data very very rapidly, under a second on the production hardware. But at times it would take anywhere between fifteen seconds and two minutes to fully send all the categorized data to AWS.
This didn’t make any sense. Acquia uses AWS servers for our Cloud Environments. We could see the data being parsed very quickly, but when it came time to actually send it, it ground to a halt. Eventually, after much troubleshooting and debugging, we realized that the sending queue was taking much longer to execute than we imagined. Each time we pushed a payload out of the pipeline, it was causing a log jam that got worse and worse. We were, essentially, parsing data faster than we could send it.
The thing we found that made the most impact on this was implementing the Command Pool. With the Command Pool, we can parallelize the actual transmission of data to AWS. This cuts down on the number of authentications we have to make, and it clears the log jam before it can form. Once we implemented the Command Pool and jacked up the concurrency, we instantly saw our communication lag fall back into acceptable levels. Most iterations of the arrivals pipeline (which is by far the most data at any time) breaks down as acquire and parse data in roughly one second and sending data in three to four seconds.
Frontend
The first proof of concept of our system relied heavily on a backbone.js frontend. Backbone was able to handle all of the procedural logic needed to acquire data, parse it, and display it. As we moved into the second phase and the new architecture, we opted to move to a more traditional “headless” or “decoupled” Drupal implementation. We rebuilt the entire front end from the ground up using React and nested it inside of a Drupal theme. We realize that usually a headless Drupal has a stand alone front end, so in this case we have coined the term “nearly headless” Drupal. Draw your own pop-culture parallels as you see fit.
A nearly headless Drupal in this case was critical, as the front end needs much of the same context from our content model as the categorizer and sender classes do. The sign can’t subscribe to the correct websocket if it doesn’t know which websocket to subscribe to. It can’t authenticate against our services if it doesn’t have the proper credentials. By deploying the React application from within a Drupal theme, we can still use PHP on the backend to send information directly into the front end via drupalSettings and other objects. Could we have done this in a completely decoupled fashion? Clearly. But in this case, we were able to reduce the service calls between the front end and Drupal itself to get this information. Remember, with thousands of signs, we are actively trying to move away from anything that could inadvertently DOS ourselves. Requiring the signs to query and authenticate into Drupal to get credentials and other key information so that they could then authenticate into the websocket immediately creates an additional level of dependency and would significantly increase traffic to the web server itself.
Once subscribed to the websocket, the front end no longer needs the web server or Drupal. All data flows to the sign directly from the IOT. The signs may periodically need to be reloaded to receive new information from Drupal, or if anything in the front end has been changed (e.g. new styles or javascript logic). Other than that, once bootstrapped, the sign is largely an independent vehicle that operates entirely within the React application running in its browser.
React was an ideal choice in this case, as so much of what the front end must do is wait for data and then change display logic based on the payload. Is there arrivals data? Great, show that template. Does one of the arrivals have a 0 as the estimated time? Start flashing. If an error is sent, or a slideshow, or a different weather condition, React has to interpret each of the business rules for these situations based only on the incoming data and then manipulate the screen to show the proper template(s).
Seeing a sign update in real time as data changes is a very rewarding experience. However, one significant downside to this model is that the sign must be connected to the internet to receive data with a valid / connected browser session running at all times. A robust infrastructure that the sign can rely on is critical. It is also critical that the front end be able to recover from disconnects or other errors. In our case, React facilitates all of our error handling. It can even recover from an Internet outage.
Remember, the data pipeline and its performance are a critical piece of this puzzle, but without the right front end application managing connection to the websocket, recovery from errors, and managing all of the display logic for what to do with the incoming data, you are still a long way away from having a functional sign.
Conclusion
The combination of object oriented PHP, React, Drupal, and Amazon Web Services Internet of Things has created a very powerful digital experience. These technologies all work together to facilitate a nearly real-time delivery of data for the MTA, which has hundreds of stations and platforms, thousands of screens, and thousands of trains running throughout the city during the day, all to serve those 11 million riders. It is an exciting development for Drupal and AWS, as this use case, while a great fit for the technologies, is not one that has been fully realized before. Sure, people have used Drupal for digital signs, but to the best of our knowledge, this is the first time a mass transit system has used this combination of technologies to implement a solution.
If this article has piqued your interested, or you are excited about working on next generation digital experiences for mass transit, check out the MTA's open positions at http://web.mta.info/mta/employment.





